A Gentle Guide to the complexities of model deployment, and integrating with the enterprise application and data pipeline. What the Data Scientist, Data Engineer, ML Engineer, and ML Ops do, in Plain English.
Ketan Doshi
Jun 28 · 11 min read
Let’s say we’ve identified a high-impact business problem at our company, built an ML (machine learning) model to tackle it, trained it, and are happy with the prediction results. This was a hard problem to crack that required much research and experimentation. So we’re excited about finally being able to use the model to solve our user’s problem!
However, what we’ll soon discover is that building the model itself is only the tip of the iceberg. The bulk of the hard work to actually put this model into production is still ahead of us. I’ve found that this second stage could take even up to 90% of the time and effort for the project.
So what does this stage comprise of? And why is it that it takes so much time? That is the focus of this article.
Over several articles, my goal is to explore various facets of an organization’s ML journey as it goes all the way from deploying its first ML model to setting up an agile development and deployment process for rapid experimentation and delivery of ML projects. If you’re interested, here’s my other article on this topic:
In order to understand what needs to be done in the second stage, let’s first see what gets delivered at the end of the first stage.
What does the Model Building and Training phase deliver?
Models are typically built and trained by the Data Science team. When it is ready, we have model code in Jupyter notebooks along with trained weights.
- It is often trained using a static snapshot of the dataset, perhaps in a CSV or Excel file.
- The snapshot was probably a subset of the full dataset.
- Training is run on a developer’s local laptop, or perhaps on a VM in the cloud
In other words, the development of the model is fairly standalone and isolated from the company’s application and data pipelines.
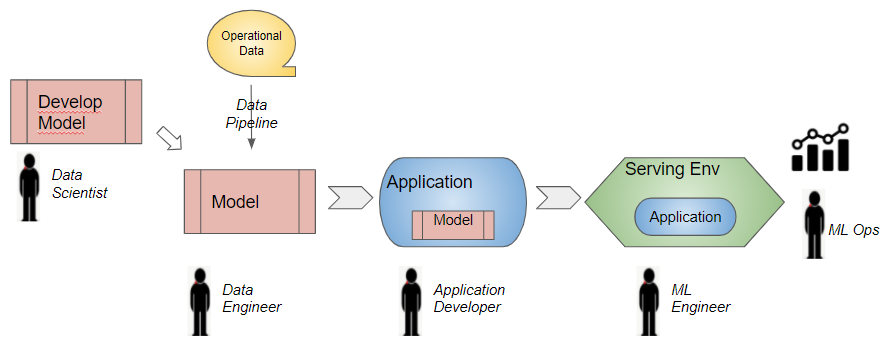
Real-time Inference and Retraining in Production (Image by Author)
What does “Production” mean?
When a model is put into production, it operates in two modes:
- Real-time Inference — perform online predictions on new input data, on a single sample at a time
- Retraining — for offline retraining of the model nightly or weekly, with a current refreshed dataset
The requirements and tasks involved for these two modes are quite different. This means that the model gets put into two production environments:
- A Serving environment for performing Inference and serving predictions
- A Training environment for retraining
Real-time Inference is what most people would have in mind when they think of “production”. But there are also many use cases that do Batch Inference instead of Real-time.
- Batch Inference — perform offline predictions nightly or weekly, on a full dataset
Batch Inference and Retraining in Production (Image by Author)
For each of these modes separately, the model now needs to be integrated with the company’s production systems — business application, data pipeline, and deployment infrastructure. Let’s unpack each of these areas to see what they entail.
We’ll start by focusing on Real-time Inference, and after that, we’ll examine the Batch cases (Retraining and Batch Inference). Some of the complexities that come up are unique to ML, but many are standard software engineering challenges.
Inference — Application Integration
A model usually is not an independent entity. It is part of a business application for end users eg. a recommender model for an e-commerce site. The model needs to be integrated with the interaction flow and business logic of the application.The application might get its input from the end-user via a UI and pass it to the model. Alternately, it might get its input from an API endpoint, or from a streaming data system. For instance, a fraud detection algorithm that approves credit card transactions might process transaction input from a Kafka topic.
Similarly, the output of the model gets consumed by the application. It might be presented back to the user in the UI, or the application might use the model’s predictions to make some decisions as part of its business logic.
Inter-process communication between the model and the application needs to be built. For example, we might deploy the model as its own service accessed via an API call. Alternately, if the application is also written in the same programming language (eg. Python), it could just make a local function call to the model code.
This work is usually done by the Application Developer working closely with the Data Scientist. As with any integration between modules in a software development project, this requires collaboration to ensure that assumptions about the formats and semantics of the data flowing back and forth are consistent on both sides. We all know the kinds of issues that can crop up. eg. If the model expects a numeric ‘quantity’ field to be non-negative, will the application do the validation before passing it to the model? Or is the model expected to perform that check? In what format is the application passing dates and does the model expect the same format?
Real-time Inference Lifecycle (Image by Author)
Inference — Data Integration
The model can no longer rely on a static dataset that contains all the features it needs to make its predictions. It needs to fetch ‘live’ data from the organization’s data stores.These features might reside in transactional data sources (eg. a SQL or NoSQL database), or they might be in semi-structured or unstructured datasets like log files or text documents. Perhaps some features are fetched by calling an API, either an internal microservice or application (eg. SAP) or an external third-party endpoint.
If any of this data isn’t in the right place or in the right format, some ETL (Extract, Transform, Load) jobs may have to be built to pre-fetch the data to the store that the application will use.
Dealing with all the data integration issues can be a major undertaking. For instance:
- Access requirements — how do you connect to each data source, and what are its security and access control policies?
- Handle errors — what if the request times out, or the system is down?
- Match latencies — how long does a query to the data source take, versus how quickly do we need to respond to the user?
- Sensitive data — Is there personally identifiable information that has to be masked or anonymized.
- Decryption — does data need to decrypted before the model can use it?
- Internationalization — can the model handle the necessary character encodings and number/date formats?
- and many more…
This tooling gets built by a Data Engineer. For this phase as well, they would interact with the Data Scientist to ensure that the assumptions are consistent and the integration goes smoothly. eg. Is the data cleaning and pre-processing done by the model enough, or do any more transformations have to be built?
Inference — Deployment
It is now time to deploy the model to the production environment. All the factors that one considers with any software deployment come up:- Model Hosting — on a mobile app? In an on-premise data center or on the cloud? On an embedded device?
- Model Packaging — what dependent software and ML libraries does it need? These are typically different from your regular application libraries.
- Co-location — will the model be co-located with the application? Or as an external service?
- Model Configuration settings — how will they be maintained and updated?
- System resources required — CPU, RAM, disk, and most importantly GPU, since that may need specialized hardware.
- Non-functional requirements — volume and throughput of request traffic? What is the expected response time and latency?
- Auto-Scaling — what kind of infrastructure is required to support it?
- Containerization — does it need to be packaged into a Docker container? How will container orchestration and resource scheduling be done?
- Security requirements — credentials to be stored, private keys to be managed in order to access data?
- Cloud Services — if deploying to the cloud, is integration with any cloud services required eg. (Amazon Web Services) AWS S3? What about AWS access control privileges?
- Automated deployment tooling — to provision, deploy and configure the infrastructure and install the software.
- CI/CD — automated unit or integration tests to integrate with the organization’s CI/CD pipeline.
The ML Engineer is responsible for implementing this phase and deploying the application into production. Finally, you’re able to put the application in front of the customer, which is a significant milestone!However, it is not yet time to sit back and relax 😃. Now begins the ML Ops task of monitoring the application to make sure that it continues to perform optimally in production.
Inference — Monitoring
The goal of monitoring is to check that your model continues to make correct predictions in production, with live customer data, as it did during development. It is quite possible that your metrics will not be as good.
In addition, you need to monitor all the standard DevOps application metrics just like you would for any application — latency, response time, throughput as well as system metrics like CPU utilization, RAM, etc. You would run the normal health checks to ensure uptime and stability of the application.
Equally importantly, monitoring needs to be an ongoing process, because there is every chance that your model’s evaluation metrics will deteriorate with time. Compare your evaluation metrics to past metrics to check that there is no deviation from historical trends.
This can happen because of data drift.
Inference — Data Validation
As time goes on, your data will evolve and change — new data sources may get added, new feature values will get collected, new customers will input data with different values than before. This means that the distribution of your data could change.So validating your model with current data needs to be an ongoing activity. It is not enough to look only at evaluation metrics for the global dataset. You should evaluate metrics for different slices and segments of your data as well. It is very likely that as your business evolves and as customer demographics, preferences, and behavior change, your data segments will also change.
The data assumptions that were made when the model was first built may no longer hold true. To account for this, your model needs to evolve as well. The data cleaning and pre-processing that the model does might also need to be updated.
And that brings us to the second production mode — that of Batch Retraining on a regular basis so that the model continues to learn from fresh data. Let’s look at the tasks required to set up Batch Retraining in production, starting with the development model.
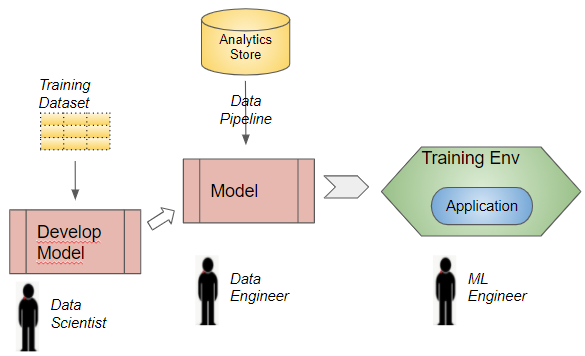 Retraining Lifecycle (Image by Author)
Retraining Lifecycle (Image by Author)
Retraining — Data Integration
When we discussed Data Integration for Inference, it involved fetching a single sample of the latest ‘live’ data. On the other hand, during Retraining, we need to fetch a full dataset of historical data. Also, this Retraining happens in batch mode, say every night or every week.Historical doesn’t necessarily mean “old and outdated” data — it could include all of the data gathered until yesterday, for instance.
This dataset would typically reside in an organization’s analytics stores, such as a data warehouse or data lake. If some data isn’t present there, you might need to build additional ETL jobs to transfer that data into the warehouse in the required format.
Retraining — Application Integration
Since we’re only retraining the model by itself, the whole application is not involved. So no Application Integration work is needed.
Retraining — Deployment
Retraining is likely to happen with a massive amount of data, probably far larger than what was used during development.You will need to figure out the hardware infrastructure needed to train the model — what are its GPU and RAM requirements? Since training needs to complete in a reasonable amount of time, it will need to be distributed across many nodes in a cluster, so that training happens in parallel. Each node will need to be provisioned and managed by a Resource Scheduler so that hardware resources can be efficiently allocated to each training process.
The setup will also need to ensure that these large data volumes can be efficiently transferred to all the nodes on which the training is being executed.
And before we wrap up, let’s look at our third production use case — the Batch Inference scenario.
Batch Inference
Often, the Inference does not have to run ‘live’ in real-time for a single data item at a time. There are many use cases for which it can be run as a batch job, where the output results for a large set of data samples are pre-computed and cached.The pre-computed results can then be used in different ways depending on the use case. eg.
- They could be stored in the data warehouse for reporting or for interactive analysis by business analysts.
- They could be cached and displayed by the application to the user when they log in next.
- Or they could be cached and used as input features by another downstream application.
For instance, a model that predicts the likelihood of customer churn (ie. they stop buying from you) can be run every week or every night. The results could then be used to run a special promotion for all customers who are classified as high risks. Or they could be presented with an offer when they next visit the site.A Batch Inference model might be deployed as part of a workflow with a network of applications. Each application is executed after its dependencies have completed.
Many of the same application and data integration issues that come up with Real-time Inference also apply here. On the other hand, Batch Inference does not have the same response-time and latency demands. But, it does have high throughput requirements as it deals with enormous data volumes.
Conclusion
As we have just seen, there are many challenges and a significant amount of work to put a model in production. Even after the Data Scientists ready a trained model, there are many roles in an organization that all come together to eventually bring it to your customers and to keep it humming month after month. Only then does the organization truly get the benefit of harnessing machine learning.We’ve now seen the complexity of building and training a real-world model, and then putting it into production. In the next article, we’ll take a look at how the leading-edge tech companies have addressed these problems to churn out ML applications rapidly and smoothly.


