AI stocks will power significantly higher over the next decade
June 23, 2021 | By Luke Lango, InvestorPlace Senior Investment Analyst
The year is 1950. The month is October. Alan Turing – the generational genius who cracked the Enigma code and helped end World War II – has just introduced a novel concept.
It’s called the “Turing Test,” and it is aimed at answering the fundamental question: Can machines think?
The world laughs. Machines? Think for themselves? Not possible.
But the Turing Test sets in motion decades of research into the emerging field of Artificial Intelligence.
It is research conducted in some of the most prestigious labs in the world, by some of the smartest people in the world, collectively working to create a new class of computers and machines that can, indeed, think for themselves.
Fast forward 70 years.
AI is everywhere.
AI is in your phones. What do you think powers Siri? Or how does a phone recognize your face?
AI is in your applications. How does Google Maps know directions and optimal routes? How does it make real-time changes based on traffic? How does Spotify create hyper-personalized playlists for you? Or Netflix recommend movies?
AI is on your computers. How does Google suggest personalized search items for you? How do websites use chatbots that seem like real humans?
As it turns out, the world shouldn’t have laughed back in 1950.
The great Alan Turing ended up creating a robust foundation upon which seven decades of groundbreaking research has compounded… year after year… ultimately resulting in self-thinking computers and machines not just being a “thing” – but being everything today.
Make no mistake. This decades-in-the-making “AI Revolution” is just getting started.
That’s because the machine learning (ML) and natural language processing (NLP) models upon which AI is built are informed with data.
Basically, the more data they have, the better the models get, and the more capable the AI becomes.
In the AI world, data is everything.
The volume and granularity of data globally is exploding right now, mostly because every object in the world is becoming a data-producing device.
Dumb phones became smartphones, and started producing bunches of phone usage data.
Dumb cars became smart cars, and started producing bunches of driving data.
Dumb apps became smart apps, and started producing bunches of consumer preference data.
Dumb watches became smart watches, and started producing bunches of fitness data.
Get the point?
As we’ve sprinted into the “Smart World” – where every object is a data-producing smart device – the amount and speed of data that AI algorithms have access to has exploded, making those AI algos more capable than ever…
Why else do you think AI has started popping up everywhere in recent years? It’s because 90% of the world’s data was generated in the last two years alone.
More data. Better ML and NLP models. Smarter AI.
It’s that simple.
And guess what? The world isn’t going to take any steps back in terms of this “smart” pivot. No. We love our smartphones, and smart cars, and smartwatches too much.
Instead, society is going to accelerate in this transition. Globally, the world produces about 2.5 exabytes of data per day today. By 2025, that number is expected to rise to 463 exabytes.
Let’s go back to our process…
More data. Better ML and NLP models. Smarter AI.
Thus, as the volume of data produced daily soars more than 185X over the next five years, ML and NLP models will get 185X better (more or less), and AI machines will get 185X smarter (more or less).
Folks… the AI Revolution is just getting started.
As my friends in the AI and robotics fields like to remind me: Most things a human does, a machine will be able to do better, faster, and cheaper. If not now, then soon.
Given the advancements AI has made over the past few years with the help of data – and the huge flood of data set to come online over the next few years – I’m inclined in believe them.
Eventually – and inevitably – the world will be run by hyperefficient and hyperintelligent AI.
I’m not alone in thinking this. Gartner predicts that 69% of routine office work will be fully automated by 2024, while the World Economic Forum has said that robots will handle 52% of current work tasks by 2025.
The AI Revolution is coming – and it’s going to be the biggest revolution you’ve ever seen in your lifetime.
As a hypergrowth investor, you need to be invested in this emerging technological megatrend that promises to change the world forever.
But, alas, the question remains: What AI stocks should you start buying right now?
You could play it safe, and go with the blue-chip tech giants, all of whom are making inroads with AI and represent low-risk, low-reward plays on the AI Revolution. I’m talking Microsoft (MSFT), Alphabet (GOOG), Amazon (AMZN), Adobe (ADBE), and Apple (AAPL).
Or, you could go for the “picks-and-shovels” chip-makers that are making the processing units upon which AI is developed. Those stocks offer a little more upside potential, but are still in the mid-risk, mid-reward category. Nvidia (NVDA) stands out for its world-class GPUs, and Advanced Micro Devices (AMD) comes to mind as the upstart in the industry with a lot of room to grow.
Or, you could go bigger with AI-specific software companies. These are smaller, more specialized, and singularly-focused tech companies that have a lot to gain in the even their AI efforts pay off.
In this category, you can go for the mid-cap stocks that with less risk, but less reward potential. Sound like a match for you? Consider these names:
- Enterprise AI software developer C3.ai (AI), who is creating modular enterprise AI applications for use specifically in the oil and gas industries;
- Low-code application platform provider Appian (APPN), who is leveraging AI to enable businesses to make automatable apps without doing any coding;
- Data-science firm Palantir (PLTR), who is using AI to bring Batman-like technology to the real world;
- Music streaming pioneer Spotify (SPOT), who is combining AI with its huge music dataset to improve new music discovery and create hyperpersonalized playlists for subscribers;
- Databasing firm Snowflake (SNOW), who is creating the foundational database upon which ML and AI models can be built with ease.
- Game design engine Unity Software (U), who is enabling its developers to use to AI to make more compelling gameplay.
Those are great AI stocks to buy today. But are they the best? Are they the ones that will score you 10X returns?
No. Instead, if you’re looking for 10X returns in the AI Revolution, you need to look in the small-cap world, where you have some early-stage companies pioneering potentially game-changing AI technologies that will, in time, unlock significant economic value.
I’m talking companies you’ve never heard of, but which are working on some very promising tech…
Companies like BigBear.ai (GIG) who is using AI to improve military operations, Stem (STEM) who is using AI to save you money on your electricity bill, LivePerson (LPSN) who is using AI to create virtual chatbots that don’t suck, and Editas (EDIT) who is using AI to cure blindness.
These small-cap AI stocks do have 10X upside potential in the AI Revolution.
So, go ahead and buy them, and if you want more picks, keep reading…
Because in my ultra-exclusive newsletter subscription service, Innovation Investor, I’m creating the ultimate portfolio of emerging megatrends and the individual companies leading them. These are stocks with the potential to score 10X-plus gains over the near- to long-term.
In fact, I have more than 40 hypergrowth stocks that could score investors Amazon-like returns over the next few months and years.
These stocks include the world’s most exciting autonomous vehicle startup, a world-class “Digitainment” stock creating the building blocks of the metaverse, a company that we fully believe is a “Tesla-killer,” and stocks emerging as leaders in artificial intelligence and machine learning.

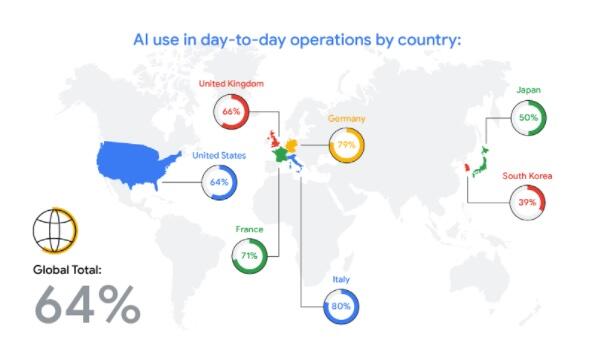


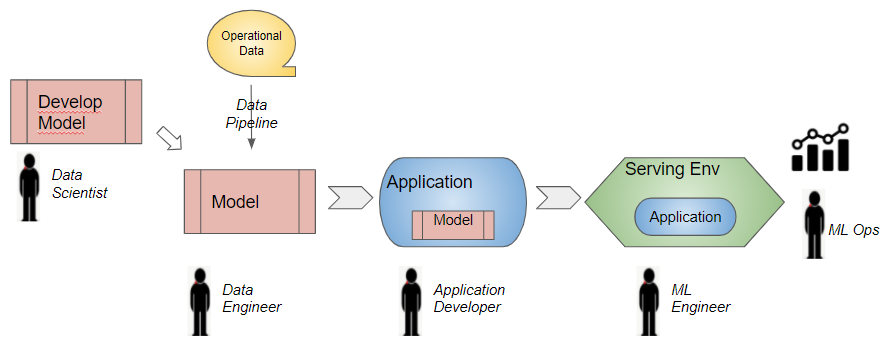
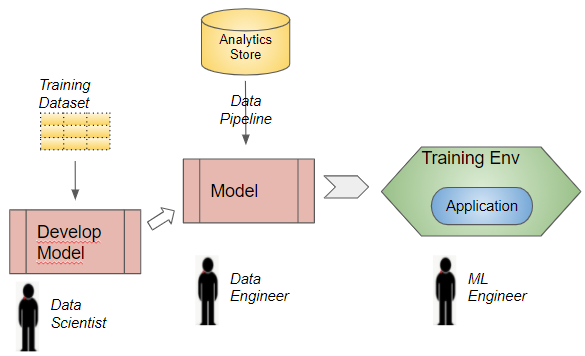 Retraining Lifecycle (Image by Author)
Retraining Lifecycle (Image by Author)